

2 min read
What it Means to Have Strategic Investors
In the world of company financing, investors are—at a high level—generally grouped into “financial investors” and “strategic investors.”
Read More2 min read
In the world of company financing, investors are—at a high level—generally grouped into “financial investors” and “strategic investors.”
Read More2 min read
In the world of company financing, investors are—at a high level—generally grouped into “financial investors” and “strategic investors.” Financial...
3 min read
Spotlight: Ezgi Bereketli, Data Engineering Product Manager Technical and open minded, Ezgi Bereketli applies quantitative and creative thinking to...

3 min read
Spotlight: Ezgi Bereketli, Data Engineering Product Manager
1 min read
We have a number of core company values which guide how we operate and how we see ourselves at Crux. One of these key values is to be a learning...
1 min read
We have a number of core company values which guide how we operate and how we see ourselves at Crux. One of these key values is to be a learning...
We’re delighted to welcome Exchange Data International’s (EDI) comprehensive and complete reference and corporate action datasets to the Crux...
2 min read
Spotlight: Jonathan Major, Head of Engineering and Operations With nearly 20 years of experience in engineering and management, Jonathan Major...
I like to think of getting projects done as ‘charging up mountains’. I appreciate the intense concerted effort and determination needed to do that,...

2 min read
Spotlight: Jonathan Major, Head of Engineering and Operations With nearly 20 years of experience in engineering and management, Jonathan Major...
We’re delighted to welcome SafeGraph’s geolocation data products to the Crux platform! SafeGraph is a geolocation data provider that maintains...

2 min read
In the world of Data Engineering, the acronym “ETL” is standard short-hand for the process of ingesting data from some source, structuring it, and...
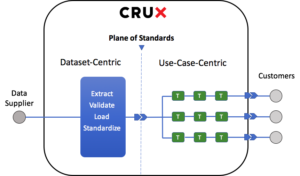
2 min read
In the world of Data Engineering, the acronym “ETL” is standard short-hand for the process of ingesting data from some source, structuring it, and...
2 min read
Hello from the CEO The Crux team has ramped up our rhythm, and our efforts are reverberating in the marketplace. As you may have heard, Citi...
1 min read
NEW YORK, March 1, 2018 /PRNewswire/ —Crux Informatics, a leading data engineering and information supply chain operator, announced a...
3 min read
Hello from the CEO Delightful data is useful and useable. Data Scientists make data useful through analysis that extracts valuable insights from...
Originally published November 8, 2017 at Reuters
Originally published November 8, 2017 at American Banker
Originally published November 8, 2017 at Techcrunch
Originally published November 8, 2017 at Business Insider
3 min read
NEW YORK and SAN FRANCISCO, Nov. 8, 2017 / PRNewswire/ — With the volume and variety of data exploding year-over-year, extracting value has never...


